Back when JavaScript was developed as Mocha at Netscape Communications Corporation by Brendan Eich in 1995, the language was meant for adding programmability on the web - making the web more interactive for the user. Over the years, JavaScript has gained massive prominence and has become one of the most important languages of the day. The rise of the web has taken JavaScript places it was never conceived to be.
Anyone who has written considerable amount of code in JavaScript will not be surprised to know that JavaScript was written in 10 days. As lovable as it may be, JavaScript has subtle bug friendly features and lot of other things that programmers would rather not have. But it is one of the essential programming(scripting?) languages in today’s web driven world. Hence, it is imperative to implement the best of software programming techniques and technologies in JavaScript.
As JavaScript grew out of its bounds, lots and lots of features were added on the go which weren’t thought of initially. The addition of all these unanticipated features, from functional programming to OOP, were pretty much work arounds of existing language features. One of the cool features added to JS in the recent years was the ability to parallel compute JavaScript and this will the focus of the following article.
You might ask why parallelize JavaScript, after all you use on the browser for small scale scripting. Sure, if you using JavaScript for an onclick handler or for a simple animation effect, you do not need parallelization. However, there are many heavyweight JS applications on the web that do a lot of procesing in JavaScript:
Client-side image processing (in Facebook and Lightroom) is written in JS; in-browser office packages such as Google Docs are written in JS; and components of Firefox, such as the built-in PDF viewer, pdf.js, and the language classifier, are written in JS. In fact, some of these applications are in the form of asm.js, a simple JS subset, that is a popular target language for C++ compilers; game engines originally written in C++ are being recompiled to JS to run on the web as asm.js programs.
The amount JavaScript in a webpage is steadily increasing over the years and the reason to parallelize JS is same as the reason to parallelize any other langauge: Moore’s law is dying and multi-core architecture is taking over the world.
JavaScript is no longer confined to the browser. It runs everywhere and on anything, from servers to IoT devices. Many of these programs are heavy-weight and might tremendously benefit from the fruits of parallel computing. The campaign to javascript everything has succeded in a way and finding ways to parallel compute JavaScript in non-browser environments is now important.
Perhaps the most solid obstacle to parallel programming in JS was its event based paradigm.
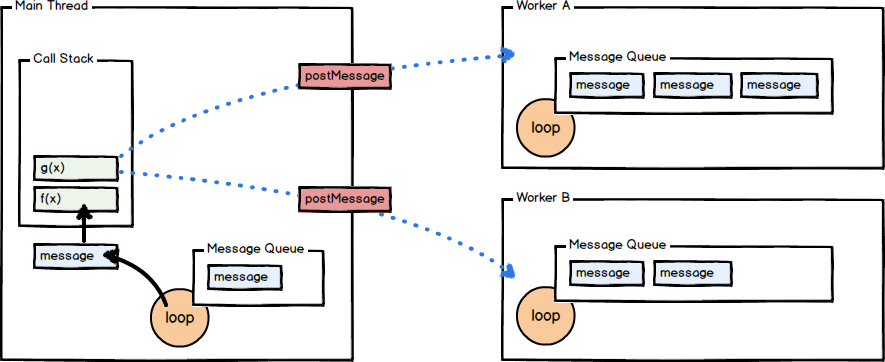
JavaScript has a concurrency model based on an “event loop” where almost all I/O is non-blocking. When the operation has been completed, a message is enqueued along with the provided callback function. At some point in the future, the message is dequeued and the callback fired.
The independence of the caller from the response allows for the JS runtime to do other things while waiting for the asynchronous operation to complete and their callbacks to trigger.
JavaScript runtimes contain a message queue which stores a list of messages to be processed and their associated callback functions. These messages are queued in response to external events (such as a mouse being clicked or receiving the response to an HTTP request) given a callback function has been provided.
The runtime has a single thread listening to events, when one of the events fire the main thread calls the requisite callback function and runs it in the background. Once the event is handled, it returns back to the main thread. This way, the single event loop can handle any number of events because the main event loop is non-blocking. This same model is implemented regardless of where JavaScript runs, in the client side or the server side(or practically anywhere else).
Now, if we were to parallelize JavaScript by having multiple threads, then by definition, each thread would be listening to the event. On the occurance of the said event, it is not possible to determine which thread or how many threads will handle the event. It is very possible that all the threads handle the same event and the single event gets handled n number of times, where n is the number of threads. So, it suffices to say that the normal paradigm of parallel computing wouldn’t work. JavaScript needs something more “JavaScripty” - another work around in the long array of JavaScript work arounds.
Normally in order to achieve any sort of parallel computation using JavaScript you would need to break your jobs up into tiny chunks and split their execution apart using timers. This is both slow and unimpressive.
Thanks to web workers, we now have a better way to achieve this.
Parallel computing in JavaScript can be achieved through Web Workers API, which were introduced with the HTML5 specification.
A web worker, as defined by the World Wide Web Consortium (W3C) and the Web Hypertext Application Technology Working Group (WHATWG), is a JavaScript script executed from an HTML page that runs in the background, independently of other user-interface scripts that may also have been executed from the same HTML page. Web workers are often able to utilize multi-core CPUs more effectively. Web workers are relatively heavy-weight. They are expected to be long-lived, have a high start-up performance cost, and a high per-instance memory cost.
Web workers allow the user to run JavaScript in parallel without interfering the user interface. A worker script will be loaded and run in the backgroud, completely independent of the user interface scripts. This means that the workers do not have any access to the user interface elements, such as the DOM and common JS functions like getElementById(You can still make AJAX calls using Web Workers). The prime use case of the web worker API is to perform computationally expensive task in the background, without interrupting or being interrupted by user interaction.
With web workers, it is now possbile to have multiple JS threads running in parallel. It allows the browser to have a normal operation with the event loop based execution of the single main thread on the user side, while making room for multiple threads in the background. Each web worker has a separate message queue, event loop, and memory space independent from the original thread that instantiated it.
Web workers communicate with the main document/ the main thread via message passing technique. The message passing is done using the postMessage API.
According to the scpecification, there are two types of web workers: shared web workers and dedicated web workers.
The default web worker is the dedicated web worker.
A dedicated worker is only accessible from the script that first spawned it, whereas shared workers can be accessed from multiple scripts.
The shared web worker needs a different constructor: SharedWorker
A shared worker is accessible by multiple scripts — even if they are being accessed by different windows, iframes or even workers.
Let’s start with the worker. The worker can have a handler to the onmessage event and it communicates with the main thread using postMessage API.
onmessage = function(e) {
console.log('Message received from main script');
//CPU intensive computations
console.log('Posting message back to main script');
postMessage(result);
}
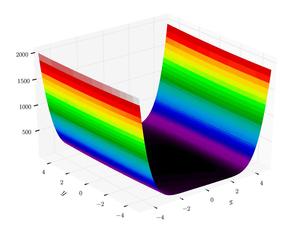
I will implement the three-hump camel function in the background using web workers and send over the result using the postMessage API.
The function:

In our task.js:
onmessage = function(e) {
console.log("Message received from main script.");
// Implementing three hump camel function
var x = e.data[0];
var y = e.data[1];
var result = (2*x*x) - (1.05*x*x*x*x) + (Math.pow(x,6)/6) + (x*y) + (y*y);
var workerResult = "Result: " + result;
console.log("Posting message back to main script.");
postMessage(workerResult);
}
On the event of the main thread sending the message the onmessage and the function executes. The worker computes the function in the background and put the message in the message queue through the postMessage function.
Now, coming to our main thread:
function compute(){
if (window.Worker) { // Check if the Browser supports the Worker api.
// Requires script name as input
var worker = new Worker("task.js");
worker.postMessage([0.554,2]); // Sending message as an array to the worker
console.log('Message posted to worker');
worker.onmessage = function(e) {
console.log(e.data);
document.getElementById("result").innerHTML = e.data;
console.log('Message received from worker');
};
}
}
We have one function compute that executes on a button onclick. We first check if the browser supports web worker API. Then we create a worker using the Worker() constructor. After which we post the data to the worker using the postMessage() function. This will run the worker script in the background, since the worker script is waiting for our message event.
We then wait for the message event from the worker. We handle that event with our callback and update the result.
The result for the given parameters:

Web workers are very good at task parallelism. One can create many background workers and run multiple tasks independently in parallel. In this example, I will go ahead and implement quicksort and mergesort to run in parallel to each other.
First, the serial code
Quicksort:
function swap(items, firstIndex, secondIndex){
var temp = items[firstIndex];
items[firstIndex] = items[secondIndex];
items[secondIndex] = temp;
}
function partition(items, left, right) {
var pivot = items[Math.floor((right + left) / 2)],
i = left,
j = right;
while (i <= j) {
while (items[i] < pivot) {
i++;
}
while (items[j] > pivot) {
j--;
}
if (i <= j) {
swap(items, i, j);
i++;
j--;
}
}
return i;
}
function quickSort(items, left, right) {
var index;
if (items.length > 1) {
index = partition(items, left, right);
if (left < index - 1) {
quickSort(items, left, index - 1);
}
if (index < right) {
quickSort(items, index, right);
}
}
return items;
}
Mergesort:
function mergeSort(arr){
if (arr.length < 2)
return arr;
var middle = parseInt(arr.length / 2);
var left = arr.slice(0, middle);
var right = arr.slice(middle, arr.length);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right){
var result = [];
while (left.length && right.length) {
if (left[0] <= right[0]) {
result.push(left.shift());
} else {
result.push(right.shift());
}
}
while (left.length)
result.push(left.shift());
while (right.length)
result.push(right.shift());
return result;
}
Now, in order for these tasks to run in parallel, we need to create a worker process for each of these:
onmessage = function(e) {
console.log("Message received from main script.");
// Implementing three hump camel function
var arr = e.data;
console.log(arr);
result = quickSort(arr, 0, arr.length - 1);
postMessage(result);
}
onmessage = function(e) {
console.log("Message received from main script.");
// Implementing three hump camel function
var arr = e.data;
console.log(arr);
result = mergeSort(arr);
postMessage(result);
}
In our main.js, we need to create and call both the woekers.
function bothsort(){
if (window.Worker) { // Check if the Browser supports the Worker api.
// Requires script name as input
var worker = new Worker("mergesort.js");
var worker_2 = new Worker("quicksort.js");
array= []
for(i =1000; i > 0; i--){
array.push(Math.round(Math.random()*1000));
}
worker.postMessage(array); // Sending message as an array to the worker
worker_2.postMessage(array); // Sending message as an array to the worker
worker.onmessage = function(e) {
console.log(e.data);
document.getElementById("result").innerHTML = e.data;
console.log('MergeSort Message received from worker');
};
worker_2.onmessage = function(e) {
console.log(e.data);
document.getElementById("result_2").innerHTML = e.data;
console.log('QUickSort Message received from worker');
};
}
}
Now, let’s time both serial and parallel tasks through window.performance.now:
a = performance.now();
bothsort();
b = performance.now();
console.log(b-a);
a = performance.now();
mergeSort(array);
quickSort(array, 0, array.length-1);
b = performance.now();
console.log(b-a);
Once the parallelization of a task is complete, it is important to evaluate the speed and efficiency of the new program, for parallelism is pointless without faster execution.
Speedup (Sp) is defined as the ratio of runtime for a sequential algorithm (T1) to runtime for a parallel algorithm with p processors (Tp). That is, Sp = T1 / Tp. Ideal speedup results when Sp = p. Speedup is formally derived from Amdahl’s law, which considers the portion of a program that is serial vs. the portion that is parallel when calculating speedup.
Here are the results for serial and parallel after many runs:
| Number of Data points | Serial | Parallel | Speedup |
|-----------------------|-------------|-------------|---------|
| 400 | 9.165000 | 1.855000 | 4.9407 |
| 800 | 11.10500 | 1.225000 | 9.0653 |
| 1600 | 20.099999 | 3.545000 | 5.6699 |
| 3200 | 45.905000 | 4.929999 | 9.3113 |
| 6400 | 93.797550 | 5.265000 | 17.8153 |
| 12800 | 288.005 | 9.44499 | 30.4298 |
The advantages of parallel processing are apparent; with a speed up of 4.9407 (4.9x faster exec time). We can also observe the performance going off the charts for 12800 elements to sort, with the speed-up reaching the massive value of 30.4298.
The graph representing the speedup:
One of the heaviest tasks on the client side is image processing. In this section, I will try to include web workers in the opensource source javascript image manipulation library pixelify.js - the library converts any image into a pixelated one in run time.
As discussed before, the web workers have no access to the DOM elements, hence, any part of code that needs to access the DOM is inherently non-parallelizable. The work around for this is to send messages to the main thread with some sort of coding that tells the main thread what action to take in the DOM, this has a lot of overhead if the workers have to interactive with the DOM on a regular basis. In addition, web workers cannot listen to the any user generated events (such as onclick), so any client-side interaction will have to be in single threaded main loop (which then, ofcourse, can call the worker).
Furthermore, web workers use the postMessage API for communicating with the main thread, which is essentially reserved for messaging through strings. The browsers use the Structured clone algorithm to pass along Complex Objects, Files and Blobs. However, this doesn’t mean that the algorithm provides an all powerful mechanism. There are restraints(and rightfully so). The structured clone algorithm does not work with many structures:
Error and Function objects cannot be duplicated by the structured clone algorithm; attempting to do so will throw a DATA_CLONE_ERR exception. Attempting to clone DOM nodes will likewise throw a DATA_CLONE_ERR exception. Certain parameters of objects are not preserved
Pixelify.js uses the canvas element from HTML5 to make the image manipulations. This means that the web workers cannot access the canvas if it is part of the DOM. In case the canvas element isn’t part of the DOM, we still cannot pass the canvas object from the main thread to the worker because of the restrictions of the postMessage API, which won’t allow objects with function to be passed along. This inhibits any parallelism when the canvas object is involved. Actual procedures/manipulations done of the canvas must remain in the main thread.
One of the shortcomings of the postMessage is parallelization of object oriented code. You cannot pass function object to the worker, hence you just cannot pass context object - this - from your object oriented code.
I had to use a work around to deal with this issue. First, I seperated out the context this into the consituent parts that would be needed by this worker. Then after processing I got back the parameters into the main thread and then applied to results in the main thread, this will be much clear once we look at the code.
From Pixelify.js code, the parallelizable region from the code is the calculation of the canvas parameters:
for (y = 0; y <= this.h + hs; y += this.pixel) {
yy = y;
if (yy >= this.h) yy = this.h - this.pixel + hs;
for (x = 0; x <= this.w + hs; x += this.pixel) {
xx = x;
if (xx >= this.w) xx = this.w - this.pixel + hs;
image_index = (yy * (this.w * 4)) + (xx * 4);
r = data[image_index];
g = data[image_index + 1];
b = data[image_index + 2];
a = (this.alpha * data[image_index + 3]) / 255;
rgba = 'rgba(' + r +','+ g +','+ b +','+ a + ')';
this[this.clean ? '_contextClean' : '_context'].fillStyle = rgba;
this[this.clean ? '_contextClean' : '_context']
.fillRect( (this.x + x) - hs, (this.y + y) - hs, this.pixel, this.pixel )
}
}
From the looks of it, this isn’t much of a CPU intensive task. This might not bode well with the web workers. Well, there’s only one way to find out for sure. So, let’s jump right into the code.
Initially, I will use a single web worker and then add multiple of them if the results seem encouraging.
In our main library file pixelify - parallel.js, let’s set up a web worker and send over the required parameters through a message - inside the pixelate function. This is workaround since directly passing this context will result in a DATA_CLONE_ERR.
var worker = new Worker("pix.js");
// Sending message as an array to the worker
worker.postMessage([this.h , this.pixel, this.w, this.x, this.y, hs, data, this.alpha]);
// storing the current context in a variable.
var pxo = this;
Now, let’s listen to the message from the worker. In our worker, we will send over the message once we have computed our values.
worker.onmessage = function(e) {
console.log(e.data);
pxo.replace();
// More to come soon
}
In in our worker file, pix.js we will listen to the onmessage event and re-assemble the split parameters sent from the main thread.
onmessage = function(e){
this.h = e.data[0];
this.pixel = e.data[1];
this.w = e.data[2];
this.x = e.data[3];
this.y = e.data[4];
hs = e.data[5];
data = e.data[6];
this.alpha = e.data[7];
Then we will initialize the result object, this is where the result will be stored and sent back to the main thread.
result = {rgbas: [], rect: []};
Now, the actual computation
for (y = 0; y <= this.h + hs; y += this.pixel) {
yy = y;
result.rgbas.push([])
result.rect.push([])
if (yy >= this.h) yy = this.h - this.pixel + hs;
for (x = 0; x <= this.w + hs; x += this.pixel) {
xx = x;
if (xx >= this.w) xx = this.w - this.pixel + hs;
image_index = (yy * (this.w * 4)) + (xx * 4);
r = data[image_index];
g = data[image_index + 1];
b = data[image_index + 2];
a = (this.alpha * data[image_index + 3]) / 255;
rgba = 'rgba(' + r +','+ g +','+ b +','+ a + ')';
result.rgbas[y/this.pixel].push(rgba);
result.rect[y/this.pixel].push([(this.x + x) - hs, (this.y + y) - hs, this.pixel, this.pixel]);
}
}
postMessage(result);
Back in our main pixelity.js file, we now have to apply the results to the DOM element. Unfortunately, we will have to have another nested for loop just to apply the results to the canvas object.
worker.onmessage = function(e) {
console.log(pxo._context)
for (y = 0; y <= pxo.h + hs; y += pxo.pixel) {
for (x = 0; x <= pxo.w + hs; x += pxo.pixel) {
pxo[this.clean ? '_contextClean' : '_context'].fillStyle = e.data.rgbas[y/10][x/10];
pxo[this.clean ? '_contextClean' : '_context']
.fillRect( (pxo.x + x) - hs, (pxo.y + y) - hs, pxo.pixel, pxo.pixel )
}
}
pxo.replace();
};
The rest of the code essentially remains the same.
I have with me an image of Konrad Zuse(The unsung pioneer of Computer Science) with the replica of his creation, the Z1.

After pixellation:
![]()
The speed-up is abysmal. In fact the parallel code is much much slower than the serial implmentation. For image sized ranging from 100 * 100 to 1024 * 768, the parallel implementation is around 5 to 10x slower than the serial implementation. Even if I have multiple web workers, it would be very hard to each catch up to serial performance, let alone surpass it.
this context was broken down and then reassembled by the worker.canvas object - this added an additional nested loop in the main thread - a proper obstacle to performance.Web workers bring about an exciting prospect of parallism in JavaScript. Bringing parallelism towards the JavaScript programmer is a big win.
Web workers are for CPU intensive tasks, from our example of task parallelism we have seen that web workers do well with CPU intensive tasks, with the above example reaching the speed-up of 30x with just two web workers. Web workers are not suitable when the task in hand is not CPU intensive as seen from the above image manipulation example.
The inability of working with the DOM is a one of the stark disadvantages as we have seen from the example above. Adding workarounds will hinder the performance.
All in all, web workers are an amazing for CPU intensive parallelism. Though not very suitable for tasks which require DOM interaction, they are a very valuable asset when javascript isn’t running on the webpage.
That’s it for now; if you have any comments, please leave them below.