OpenMP is one of the most popular solutions to parallel computation in C/C++. OpenMP is a mature API and has been around two decades, the first OpenMP API spec came out for Fortran(Yes, FORTRAN). OpenMP provides a high level of abstraction and allows compiler directives to be embedded in the source code.
Ease of use and flexibility are the amongst the main advantages of OpenMP. In OpenMP, you do not see how each and every thread is created, initialized, managed and terminated. You will not see a function declaration for the code each thread executes. You will not see how the threads are synchronized or how reduction will be performed to procure the final result. You will not see exactly how the data is divided between the threads or how the threads are scheduled. This, however, does not mean that you have no control. OpenMP has a wide array of compiler directives that allows you to decide each and every aspect of parallelization; how you want to split the data, static scheduling or dynamic scheduling, locks, nested locks, subroutines to set multiple levels of parallelism etc.
Another important advantage of OpenMP is that, it is very easy to convert a serial implementation into a parallel one. In many cases, serial code can be made to run in parallel without having to change the source code at all. This makes OpenMP a great option whilst converting a pre-written serial program into a parallel one. Further, it is still possible to run the program in serial, all the programmer has to do is to remove the OpenMP directives.
First, let’s see what OpenMP is:
OpenMP, short for “Open Multi-Processing”, is an API that supports multi-platform shared memory multiprocessing programming in C, C++, and Fortran - on most platforms, processor architectures and operating systems.
OpenMP consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior. So basically when we use OpenMP, we use directives to tell the compiler details of how our code shuld be run in parallel. Programmers do not have to write (or cannot write) implicit parallelization code, they just have to inform the compiler to do so. It is imperative to note that the compiler does not check if the given code is parallelizable or if there is any racing, it is the responsibility of the programmer to do the required checks for parallelism.
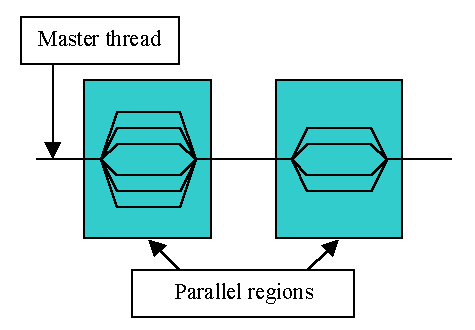
OpenMP is designed for multi-processor/core, shared memory machines and can only be run in shared memory computers. OpenMP programs accomplish parallelism exclusively through the use of threads. There’s a master thread that forks a number of slave threads that do the actual computation in parallel. The master plays the role of a manager. All the threads exist within a single process.
By default, each thread executes the parallelized section of code independently. Work-sharing constructs can be used to divide a task among the threads so that each thread executes its allocated part of the code. Therefore, both task parallelism and data parallelism can be achieved using OpenMP.
Though, not the most efficient method, OpenMP provides one of the easiest parallelization solutions for programs written in C and C++.
For our first example, let’s look at linear search.
Linear search or sequential search is a method for finding a target value within a list. It sequentially checks each element of the list for the target value until a match is found or until all the elements have been searched.
Linear search is one of the simplest algorithms to implement and has the worst case complexity of O(n), ie. the algorithm has to scan through the entire list to find the element - this happens when the required element isn’t in the list or is present right at the end.
By parallelizing the implementation, we make the multiple threads split the data amongst themselves and then search for the element independently on their part of the list.
Here’s the serial implementation:
#include <stdio.h>
#include <stdlib.h>
int linearSearch(int* A, int n, int tos);
int main(){
int number, iter =0, find;
int* Arr;
Arr = (int *)malloc( number * sizeof(int));
scanf("%d", &number);
for(; iter<number; iter++){
scanf("%d", &Arr[iter]);
}
scanf("%d", &find);
printf("\nTo find: %d\n", find);
int indx = linearSearch(Arr, number, find);
if(indx == -1)
printf("Not found");
else
printf("Found at %d\n", indx);
return 0;
}
int linearSearch(int* A, int n, int tos){
for(int iter =0; iter< n; iter++){
if(A[iter] == tos)
return iter;
}
}
In order to use OpenMP’s directives, we will have to include the header file: "omp.h". Whilst compilation, we’ll have to include the flag -fopenmp. All the directives start with #pragma omp ... .
In the above serial implementation, there is a window to parallelize the for loop. To parallelize the for loop, the openMP directive is: #pragma omp parallel for. This directive tells the compiler to parallelize the for loop below. As I’ve said before, the complier makes no checks to see if the loop is parallelizable, it is the responsiblity of the programmer to make sure that the loop can be parallelized.
Whilst parallelizing the loop, it is not possible to return from within the if statement if the element is found. This is due to the fact that returning from the if will result in an invalid branch from OpenMP structured block. Hence we will have change the implementation a bit.
int foundat = -1;
for(int iter =0; iter< n; iter++){
if(A[iter] == tos)
foundat = iter+1;
}
return foundat;
The above snippet will keep on scanning the the input till the end regardless of a match, it does not have any invalid branches from OpenMP block. Also, we can be sure that there is won’t be racing since we are not modifying any variable decalred outside. Now, let’s parallelize this:
int foundat = -1;
#pragma omp parallel for
for(int iter =0; iter< n; iter++){
if(A[iter] == tos)
foundat = iter+1;
}
return foundat;
It is as simple as this, all that had to be done was adding the comipler directive and it gets taken care of, completely. The implementation didn’t have to be changed much. We didn’t have to worry about the actual implementation, scheduling, data split and other details. There’s a high level of abstraction. Also, the code will run in serial after the OpenMP directives have been removed, albeit with the modification.
It is noteworthy to mention that with the parallel implementation, each and every element will be checked regardless of a match, though, parallely. This is due to the fact that no thread can directly return after finding the element. So, our parallel implementation will be slower than the serial implementation if the element to be found is present in the range [0, (n/p)-1] where n is the length of the array and p is the number of parallel threads/sub-processes.
Further, if there are more than one instances of the required element present in the array, there is no guarantee that the parallel linear search will return the first match. The order of threads running and termination is non-deterministic. There is no way of which which thread will return first or last. To preserve the order of the matched results, another attribute(index) has to be added to the results.
You can find the complete code of Parallel Linear Search here
Now, let’s look at our second example - Selection Sort.
Selection sort is an in-place comparison sorting algorithm. Selection sort is noted for its simplicity, and it has performance advantages over more complicated algorithms in certain situations, particularly where auxiliary memory is limited.
In selection sort, the list is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire list.
The smallest/largest element is selected from the unsorted array and swapped with the leftmost element, and that element becomes a part of the sorted array. This process continues moving unsorted array boundary by one element to the right.
Selection Sort has the time complexity of O(n2), making it unsuitable for large lists.
By parallelizing the implementation, we make the multiple threads split the data amongst themselves and then search for the largest element independently on their part of the list. Each thread locally stores it own smallest element. Then,
Here’s the serial implementation:
#include <stdio.h>
#include <stdlib.h>
void swap(int* a, int* b);
void selectionSort(int* A, int n);
int main(){
int number, iter =0;
int* Arr;
Arr = (int *)malloc( number * sizeof(int));
scanf("%d", &number);
for(; iter<number; iter++){
scanf("%d", &Arr[iter]);
}
selectionSort(Arr, number);
for(int iter=0; iter<number;iter++){
printf("%d ", Arr[iter]);
}
return 0;
}
void selectionSort(int* A, int n){
for(int startpos =0; startpos < n; startpos++){
int maxpos = startpos;
for(int i=startpos +1; i< n; ++i){
if(A[i] < A[maxpos]){
maxpos = i;
}
}
swap(&A[startpos], &A[maxpos]);
}
}
void swap(int* a, int* b){
int temp = *a;
*a = *b;
*b = temp;
}
First, let’s look at potential parallelization windows. The outer loop is not parallelizable owing to the fact that there are frequent changes made to the array and that every ith iteration needs the (i-1)th to be completed.
In selection sort, the parallelizable region is the inner loop, where we can spawn multiple threads to look for the maximum element in the unsorted array division. This could be done by making sure each thread has it’s own local copy of the local maximum. Then we can reduce each local maximum into one final maximum.
Reduction can be performed in OpenMP through the directive:
#pragma omp parallel for reduction(op:va)
where op defines the operation that needs to be applied whilst performing reduction on variable va.
However, in the implementation, we are not looking for the maximum element, instead we are looking for the index of the maximum element. For this we need to declare a new custom reduction. The ability to describe our own custom reduction is a testament to the flexibility that OpenMP provides.
Reduction can be declared by using:
#pragma omp declare reduction (reduction-identifier : typename-list : combiner) [initializer-clause]
The declared reduction clause receives a struct. So, our custom maximum index reduction will look something like this:
struct Compare { int val; int index; };
#pragma omp declare reduction(maximum : struct Compare : omp_out = omp_in.val > omp_out.val ? omp_in : omp_out)
Now, let’s work on parallelizing the inner loop through OpenMP. We’ll need to store both the maximum value as well as its index.
#pragma omp parallel for reduction(maximum:max)
for(int i=startpos +1; i< n; ++i){
if(A[i] > max.val){
max.val = A[i];
max.index = i;
}
} The above will take care of parallelizing the inner loop.
Now that we’ve parallelized our serial implementation, let’s see if the program produces the required output. For that, we can have a simple verify function that checks if the array is sorted.
void verify(int* A, int n){
int failcount = 0;
for(int iter = 0; iter < n-1; iter++){
if(A[iter] < A[iter+1]){
failcount++;
}
}
printf("\nFail count: %d\n", failcount);
}
After running the new sort implementation with the verify function for 100000 elements:
>>>Fail count: 0
So, the parallel implementation is equivalent to the serial implementation and produces the required output.
You can find the complete code of Parallel Selection sort here.
Mergesort is one of the most popular sorting techniques. It is the typical example for demonstrating the divide-and-conquer paradigm.
Merge sort (also commonly spelled mergesort) is an efficient, general-purpose, comparison-based sorting algorithm.
Mergesort has the worst case serial growth as O(nlogn).
Sorting an array: A[p .. r] using mergesort involves three steps.
1) Divide Step
If a given array A has zero or one element, simply return; it is already sorted. Otherwise, split A[p .. r] into two subarrays A[p .. q] and A[q + 1 .. r], each containing about half of the elements of A[p .. r]. That is, q is the halfway point of A[p .. r].
2) Conquer Step
Conquer by recursively sorting the two subarrays A[p .. q] and A[q + 1 .. r].
3) Combine Step
Combine the elements back in A[p .. r] by merging the two sorted subarrays A[p .. q] and A[q + 1 .. r] into a sorted sequence. To accomplish this step, we will define a procedure MERGE (A, p, q, r).
We can parallelize the “conquer” step where the array is recursively sorted amongst the left and right subarrays. We can ‘parallely’ sort the left and the right subarrays.
Here’s the serial implementation:
#include <stdio.h>
#include <stdlib.h>
void mergesort(int a[],int i,int j);
void merge(int a[],int i1,int j1,int i2,int j2);
int main()
{
int *a, num, i;
scanf("%d",&num);
a = (int *)malloc(sizeof(int) * num);
for(i=0;i<num;i++)
scanf("%d",&a[i]);
mergesort(a, 0, num-1);
printf("\nSorted array :\n");
for(i=0;i<num;i++)
printf("%d ",a[i]);
return 0;
}
void mergesort(int a[],int i,int j)
{
int mid;
if(i<j)
{
mid=(i+j)/2;
mergesort(a,i,mid); //left recursion
mergesort(a,mid+1,j); //right recursion
merge(a,i,mid,mid+1,j); //merging of two sorted sub-arrays
}
}
void merge(int a[],int i1,int j1,int i2,int j2)
{
int temp[1000]; //array used for merging
int i,j,k;
i=i1; //beginning of the first list
j=i2; //beginning of the second list
k=0;
while(i<=j1 && j<=j2) //while elements in both lists
{
if(a[i]<a[j])
temp[k++]=a[i++];
else
temp[k++]=a[j++];
}
while(i<=j1) //copy remaining elements of the first list
temp[k++]=a[i++];
while(j<=j2) //copy remaining elements of the second list
temp[k++]=a[j++];
//Transfer elements from temp[] back to a[]
for(i=i1,j=0;i<=j2;i++,j++)
a[i]=temp[j];
}
As stated before, the parallelizable region is the “conquer” part. We need to make sure that the left and the right sub-arrays are sorted simuntaneously. We need to implement both left and right sections in parallel.
This can be done in OpenMP using directive:
#pragma omp parallel sections
And each section that has to be parallelized should be enclosed with the directive:
#pragma omp section
Now, let’s work on parallelizing the both sections through OpenMP
if(i<j)
{
mid=(i+j)/2;
#pragma omp parallel sections
{
#pragma omp section
{
mergesort(a,i,mid); //left recursion
}
#pragma omp section
{
mergesort(a,mid+1,j); //right recursion
}
}
merge(a,i,mid,mid+1,j); //merging of two sorted sub-arrays
}
The above will parallleize both left and right recursion.
Now that we’ve parallelized our serial mergesort implementation, let’s see if the program produces the required output. For that, we can use the verify function that we used for our selection sort example.
>>> Fail count: 0
Great, so the parallel implementation works. You can find the parallel implementation here
That’s it for now, if you have any comments please leave them below.