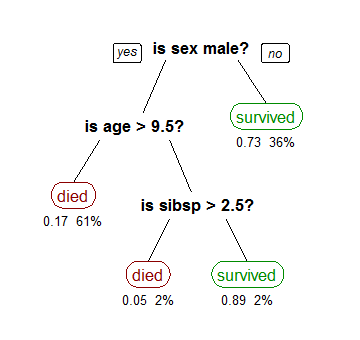
Decision tree learning is one of the most commonly known machine learning algorithms out there. One of the advantages of decision trees are that there are quite straight forward, easily understandable by humans. Decision trees provide a way to approximate discrete valued functions and are robust to noisy data. Decision trees can be represented using the typical Tree Data Structure.
Decision tree learning uses a decision tree (as a predictive model) to go from observations about an item (represented in the branches) to conclusions about the item’s target value (represented in the leaves). It is one of the predictive modelling approaches used in statistics, data mining and machine learning.
Decision tree is a supervised learning algorithm, ie. it needs training data. You will have to feed the algorithm training data for it make predictions on the actual data. Though decision trees can be utilized for both classification and regression, it’s primarily used for classification.
In my previous blog post, I had explained the theory behind Decision Tree Learning . If you are not very familiar with the algorithm, do check my previous post.
Here’s an example of a classification tree (Titanic Dataset):
In this article, I will be focusing on the Iterative Dichotomiser 3, commonly know as the ID3 algorithm. Variants/Extensions of the ID3 algorithm, such as C4.5, are very much in practical use today.
The ID3 algorithm greedily builds the tree top-down, starting from the root by meticulously choosing which attribute that will be tested at each given node. Each attribute is evaluated through statistical means as to see which attribute splits the dataset the best. The best attribute is made the root, with it’s attribute values branching out. The process continues with the rest of the attributes. Once an attribute is selected, it is not possible to backtrack.
The implementation can be divided into the following:
createTree function will build the actual decision tree based on previous functions.I’ve used the legendary “Titanic” dataset from the Kaggle. We will be create a model that predicts which passengers survived the Titanic shipwreck based on many input parameters. The predict class is binary: “survived” or “not-survived”.
I’ve modified the original data set and removed some of the columns (like passenger_id, ticket number, name, boat number etc) and I have chosen a very small and contrived subset of the data for this article. You can find it my github repo here. The remaining parameters in the data set are: pclass, survived, sex, and embarked
The original data set has the data description and other related metadata. You can find the original data set from the Kaggle here.
The first thing to do is to read the csv file. To deal with the csv data data, let’s import Pandas first. Pandas is a powerful library that gives Python R like syntax and functioning.
import pandas as pd
Now, loading the data file:
df = pd.read_csv(r".\data\titanic.csv") #Reading from the data file
Now, our task is to convert the non-numerical data elements into numerical formats. Our dataset is a mixture of numbers and character strings. The character strings are binary (sex parameter) or ternary (embarked parameter) in nature. So, we will be assigning the values of 0, 1 and 0, 1, 2 respectively.
# Sex param
df.replace('male', 0, inplace = True)
df.replace('female', 1, inplace = True)
# Embarked param
df.replace('S', 0, inplace = True)
df.replace('C', 1, inplace = True)
df.replace('Q', 2, inplace = True)
In main.py:
dataset = df.astype(float).values.tolist()
#Shuffle the dataset
random.shuffle(dataset) #import random for this
Before we move forward, let’s create a class for the algorithm.
class CustomDecisionTree:
def __init__(self):
pass
We have the CustomDecisionTree, that will be our main class for the algorithm. In the constructor, we do not have to initialize any value.
Now, let’s define the functions that go inside the CustomDecisionTree class. For our implementation, we will only need functions - calcShannonEnt, chooseBestFeatureToSplit, createTree and predict.
The calcShannonEnt function will use the training data to calculate the entropy of a given dataset. If you are unfamiliar with the terminology or the theoretical fundamentals of Decision Trees, you can refer my previous article here. The chooseBestFeatureToSplit function, as the name eloquently suggests, will predict the best feature that can split the decision tree at any given point in decision tree construction. The heuristic to define best is the information gain, which is calculated through the entropy. The createTree is a recursive function that greedily builds our decision tree from top to bottom. The createTree chooses the differentiating attribute (the attribute the splits the tree at any given node) by the decreasing order of the information gain of the attribute. This is handled at the chooseBestFeatureToSplit function. The predict function will predict the classification for the incoming parameters, deriving it from the tree built by createTree from the training dataset.
First we have the calcShannonEnt function. We only need a data set as a param for fit, that’s all we need to calculate the entropy at this point.
def calcShannonEnt(self, dataset):
pass
Let’s define the chooseBestFeatureToSplit function. The chooseBestFeatureToSplit function also takes in a dataset param. It is up to the caller which section or subset of our training dataset to pass to find the best split attribute.
def chooseBestFeatureToSplit(self, dataset):
pass
Now we have our recursive createTree function. The createTree function takes in the training dataset. The function that uses the training dataset to model the decision tree.
def createTree(self, dataset):
pass
calcShannonEnt function:The calcShannonEnt function is the core of how we model out decision tree. This is where we will calculate the entropy training data set provided. In the fit function, we will be be trying to find the entropy for for any given set of data points, essentially trying to find how much information content is present in a given set of data points.
Entropy is a measure of unpredictability of the state, or equivalently, of its average information content.
The formula for this statistical metric:
Entropy(S) = E(S) = -ppositive log2 ppositive - pnegative log2 pnegative
Where ppositive is the proportion (probability) of positive examples in S and pnegative is the proportion of negative examples in S. Entropy is 1 if the collection S contains equal number of examples from both classes, Entropy is 0 if all the examples in S contain the same example.
In general terms, when the classes of the target function may not always be boolean, entropy is defined as
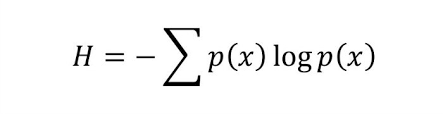
So for our case with the titanic data set, the formula would look like:
Entropy(S) = E(S) = -psurvived log2 psurvived - pnot-survived log2 pnot-survived
Implementing this in code, first we will find the count of data points of each label.
def calcShannonEnt(self, dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
Now, lets apply the formula for calculating Shannon Entropy:
shannonEnt = 0.0 # Initialize the entrypy to 0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
chooseBestFeatureToSplit function:The chooseBestFeatureToSplit function, as the name suggests, will find the best feature to split the tree for an given set of feature vectors. The function will use the information gain metric to decide which feature most optimally will split the dataset. The information gain is calculated by using Shannon Entropy. We first calulate the baseEntropy for the whole dataset and then calculate the entropy of without each subsequent feature. In order to split the dataset, we will first implement the splitDataSet function.
def splitDataSet(self, dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
Now let’s get started on the chooseBestFeatureToSplit function, let’s initialize some important params:
def chooseBestFeatureToSplit(self, dataSet, labels):
numFeatures = len(dataSet[0]) - 1
baseEntropy = self.calcShannonEnt(dataSet)
bestInfoGain = -1
bestFeature = 0
We’ve initialized the bestInfoGain to -1 and chosen the first feature as the best by default. We’ve also calculated the base entropy of the entire dataset at this point. Next, we will calculate the infoGain for each feature.
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = self.splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * self.calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
We now have the infoGain calculated for each feature, by calculating the newEntropy - the entropy for the feature in question by using the formula mentioned in the previous section. Now, we can select the feature with the highest information gain.
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
The whole funtion:
def chooseBestFeatureToSplit(self, dataSet, labels):
numFeatures = len(dataSet[0]) - 1
baseEntropy = self.calcShannonEnt(dataSet)
bestInfoGain = -1
bestFeature = 0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = self.splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * self.calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
print(infoGain, bestInfoGain)
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
print("the best feature to split is", labels[bestFeature])
return bestFeature
createTree function:Here is where we get into the meat of the implementation. We will now build the createTree function that will recursively build our tree model. We will be using the previously implemented functions for the modeling. First let add some guard code, for the cases where our classes are empty (ie. we have reach the leaf nodes) and for the case when all the the labels are the same.
classList = [example[-1] for example in dataSet]
if len(classList) is 0:
return
if classList.count(classList[0]) == len(classList):
return classList[0]
We get the list of feature vector list and then calculate the best feature to split using the chooseBestFeatureToSplit function. This is where we start building our model.
featureVectorList = [row[:len(row)-1] for row in dataSet]
bestFeat = self.chooseBestFeatureToSplit(featureVectorList, labels)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
# Get rid of the label, ie. this feature is taken care of in this iteration
del(labels[bestFeat])
Once we have the best feature to split the data set into, we will find the unique values in that feature and build our tree using them. Please bear in mind, this process will only work for discrete features. Features like pclass and sex are discrete by default. If you had a continous feature, for example, say something like age, you would have to convert that feature into a discrete feature first. You can use a method like Discrete binning for the same.
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = self.createTree(
self.splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
For each unique value of the feature, we will recursively split the dataset and call create tree for the subset of the data. We will continue this process until we hit the leaf of the decision tree - the point where the subset of the data is empty or if all the lables are of the same type. This condition is handled in the first two if statements of the createTree function.
We end up with the function:
# function to build tree recursively
def createTree(self, dataSet, labels):
classList = [example[-1] for example in dataSet]
if len(classList) is 0:
return
if classList.count(classList[0]) == len(classList):
return classList[0]
featureVectorList = [row[:len(row)-1] for row in dataSet]
bestFeat = self.chooseBestFeatureToSplit(featureVectorList, labels)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = self.createTree(
self.splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
Let’s build our decision tree model, by initializing the class and calling createTree method with our dataset from the main function.
custom_DTree = CustomDecisionTree()
print(custom_DTree.createTree(dataset, labels))
We come up with a tree which look something like this, for our contrived dataset:
{
"sex":{
0.0:{
"pclass":{
1.0:{
"embarked":{
0.0:1.0,
1.0:0.0
}
},
2.0:0.0
}
},
1.0:{
"pclass":{
1.0:1.0,
2.0:{
"embarked":{
0.0:1.0,
1.0:0.0
}
}
}
}
}
}
Once we have this model, we can start making predictions for any incoming data points or your test dataset. The implementation of the predict function is left as an exercise for the reader.
That’s it for now, if you have any comments, please leave then below.